
Jan. 3, 2025
A Medical Record is an Example of?
In this post you found detailed answer to this questions with examples.

We offer advanced de-identification solutions for DICOM files, ensuring that all patient-related information is securely removed or anonymized, while maintaining the integrity and quality of the medical images.
We specialize in de-identifying various image formats, including JPEG, PNG, and TIFF, by removing or masking patient-related details, thereby protecting patient privacy without compromising image quality.
Learn more about Image De-identification
Our PDF de-identification services ensure that all textual and graphical elements containing patient information are safely removed or redacted, preserving the document's original format and readability.
Learn more about Pdf de-identification
Efficiently extract valuable data from scanned documents and images with our advanced data extraction solutions. Our cutting-edge technology seamlessly digitizes and processes text, tables, and other critical information, enhancing productivity and accuracy. Say goodbye to manual data entry hassles and unlock the full potential of your scanned documents with our robust data extraction capabilities.
Try your document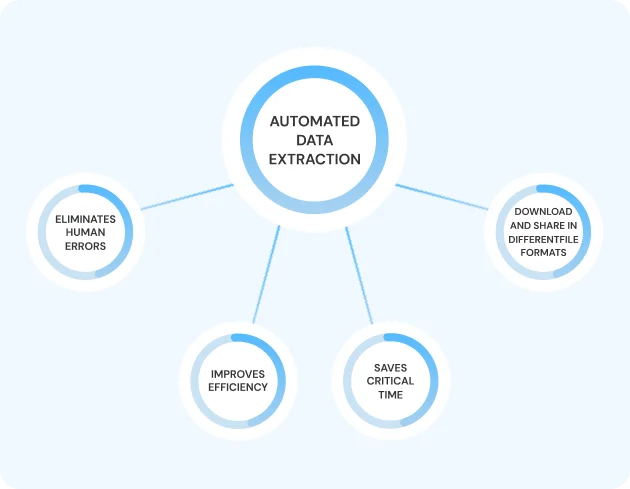

Our team comprises experienced professionals in healthcare compliance regulations, augmented by skilled Data Scientists and ML engineers. Leveraging advanced de-identification techniques, we ensure precise and dependable results, backed by years of industry expertise.

We prioritize the utmost security and confidentiality of your data. Employing robust encryption methods and stringent data protection protocols, we safeguard sensitive information throughout the de-identification process. Rest assured, your data is in safe hands.

Our de-identification processes strictly adhere to industry standards and regulations, including HIPAA, GDPR, and other pertinent privacy laws. With our comprehensive compliance measures, you can trust in full regulatory adherence and enjoy peace of mind.

Our solution offers unparalleled scalability, capable of running seamlessly on a Spark cluster or as a REST API service. Whether deployed on your isolated infrastructure or on cloud platforms like AWS, Azure, or Databricks, our solution adapts to your evolving needs with ease.

We specialize in managing large files, including DICOM and PDF formats. Our solution effortlessly handles files up to 3GB in DICOM format and up to 10,000 pages in PDF format, ensuring efficient processing of extensive datasets.

Utilizing human oversight and Generative AI, we ensure the quality of results for each document or page. Our rigorous quality control measures guarantee accurate and reliable outcomes, meeting the highest standards of excellence.

"ApicomPro's de-identification services have been instrumental in helping us maintain compliance with privacy regulations. Their team is professional, knowledgeable, and always delivers exceptional results."
Dr. Emily Johnson
Healthcare Provider

"We trust ApicomPro to handle our medical document de-identification needs. Their services are reliable, efficient, and cost-effective."
Jane Hopkins
Healthcare Administrator
In this post you found detailed answer to this questions with examples.

Discover essential data anonymization techniques that protect personal information while maintainin…

Is a phone number PII? Discover how phone numbers can be both useful and risky. Learn how to protec…
Discover how ApicomPro can help you protect sensitive information using data anonymization and comply with data protection regulations. Contact us today to learn more about our solutions and request a demo.