Automated PDF de-identification: Performance Analysis

Originally posted on Medium.
In today’s digital age, the safeguarding of sensitive information is more crucial than ever. Organizations frequently handle large volumes of documents containing personal, confidential, or proprietary data. One critical aspect of managing these documents is de-identification, the process of removing or obfuscating personal identifiable information (PII) and other sensitive data from documents. While manual de-identification is effective, it is time-consuming and prone to human error. This is where automated PDF de-identification solutions come into play, offering a blend of efficiency, accuracy, and scalability. ApicomPro provided professional service for building automated de-identification solutions based on the state-of-the-art AI models.
What is PDF De-identification?
PDF de-identification refers to the process of automatically identifying and removing or masking sensitive information in PDF documents. This can include names, addresses, social security numbers, medical records, and other PHI. The goal is to anonymize the document content without altering its overall structure and meaning, ensuring compliance with privacy regulations like GDPR, HIPAA, and CCPA.
Importance of Automated De-identification
- Efficiency: Automated systems can process large volumes of documents much faster than humans, significantly reducing the time needed for de-identification.
- Consistency: Automated solutions ensure that the same standards are applied uniformly across all documents, reducing the risk of human error.
- Scalability: Organizations can scale their de-identification efforts to match the volume of documents processed without proportional increases in human resources.
- Compliance: Automated de-identification helps ensure that documents comply with relevant privacy laws and regulations, thereby reducing legal risks.
Key Performance Metrics
When evaluating the performance of automated PDF de-identification systems, several key metrics should be considered:
1. Accuracy
Accuracy measures how effectively the system identifies and removes sensitive information. High accuracy is crucial to ensure that no PII is left undiscovered and that non-sensitive information is not mistakenly removed.
2. Speed
Speed indicates the time taken by the system to process and de-identify a document. Faster processing times enable organizations to handle larger volumes of documents in a shorter period, enhancing operational efficiency.
3. Precision and Recall
- Precision: The proportion of correctly identified sensitive information out of all identified information.
- Recall: The proportion of correctly identified sensitive information out of all actual sensitive information in the document.
A balance between precision and recall is essential for optimal performance. High precision with low recall means many sensitive data points are missed, while high recall with low precision means too much non-sensitive information is removed.
4. Scalability
Scalability measures the system’s ability to handle increasing volumes of documents without performance degradation. A scalable system can maintain high accuracy and speed even as the volume of documents grows.
5. Cost-Effectiveness
Cost-effectiveness assesses the overall value provided by the de-identification solution relative to its cost. This involves considering the initial setup costs, operational costs, and the potential savings from improved efficiency and compliance.
Case Study: Evaluating Automated De-identification Performance
To better understand the performance of automated PDF de-identification, let’s consider a case study of solution provided by theApicomPro. Needs to de-identify patient records to comply with HIPAA regulations before sharing them for research purposes.
Setup
ApicomProimplemented an automated PDF de-identification system and evaluated its performance. The system was assessed based on the key performance metrics outlined above.
Results
Accuracy
ApicomPro solutions based on state-of-the-art AI models. It is using for text detection, text recognition and for NER task. The system achieved an accuracy rate of98%, successfully identifying and removing sensitive patient information while preserving non-sensitive data.
Speed
On average, the system processed each page of the document in 0.16 seconds using GPU, enabling the provider to de-identify thousands of records daily.
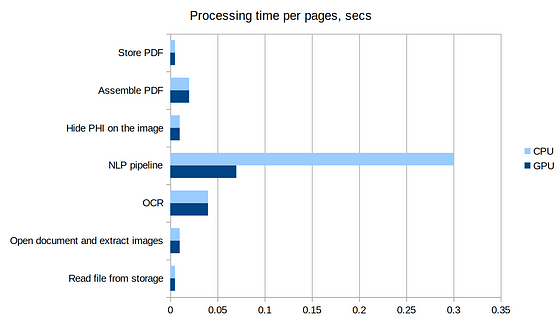
Example of benchmarksper pagefor processing 3 files with total number of pages is 410 on instance with32 CPUcores and32 GBof memory:
- Read file from storage — 0.005 s
- Open document and extract images — 0.01 s
- OCR— 0.04 s
- NLPpipeline — 0.07 s(GPU)/0.3 s(CPU) (include loading model to the memory from file system)
- Hide PHI on the image — 0.01 s
- Assemble PDF-0.02 s
- Store PDF — 0.005 s
Total: GPU — 0.16 seconds per page/CPU — 0.39 seconds per page
For process 410 pages was spent: on GPU — 63 seconds, on CPU — 160 seconds
So this instance can process 9000 pages per hour.
Precision and Recall
The solution achieved a precision rate of 97%and a recall rate of 96%, indicating a balanced performance with minimal false positives and false negatives.
Scalability
The ApicomPro solutions demonstrated excellent scalability, because it based on the Apache Spark, maintaining high performance levels as the volume of documents increased and solution demonstrate horizontal scalability by adding extra nodes to the Spark cluster dynamically without any changes in code base.

Cost-Effectiveness
The our solution created significant cost savings in de-identification PDF documents.
For exampleAWS EC2 instance m6g.8xlarge (32 CPU 128 GB) with cost 1,232 USD per hour can process about 9000 pages.
Cost of processing single page is 0.000136 USD.
For process 1M pages need 138 USD and about 4.5 days on this instance. But with scalability of the Apache Spark it can be processed during hours.
Challenges and Considerations
While automated PDF de-identification systems offer numerous benefits, there are challenges to consider:
- Complex Document Formats: Some PDFs contain complex formatting, embedded images, or handwritten notes that can pose difficulties for automated systems.
- False Positives and Negatives: Balancing precision and recall is challenging, and some level of manual review may still be necessary to ensure complete accuracy.
In the next post we will look more detail to the accuracy part.
Try your file on demo page.
Actual benchmarks you can found here.